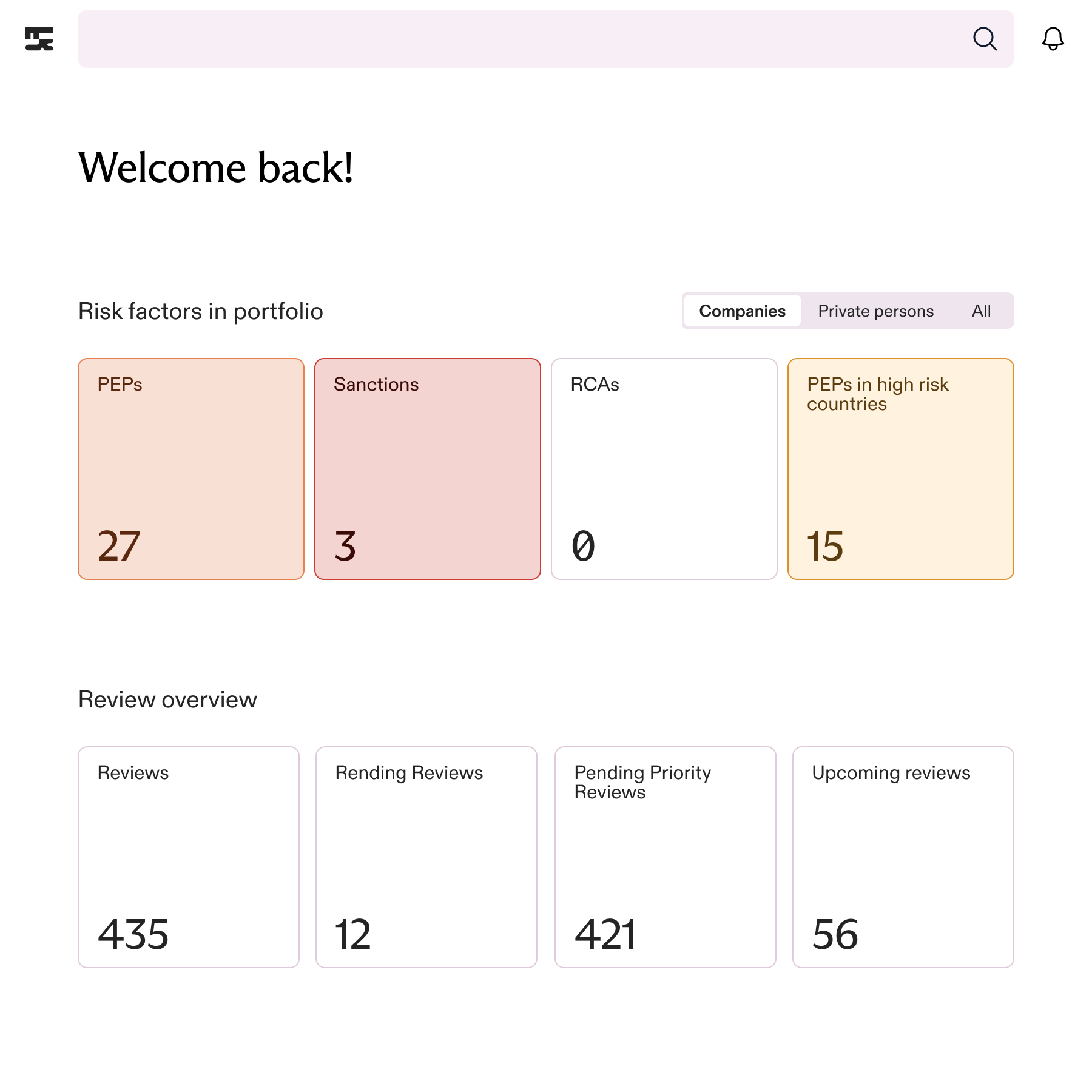
KYC remediation is the process of reviewing, updating, and correcting customer files so they meet your current data standard and regulatory requirements. For most banks, it means reopening thousands of cases, identifying what's missing or outdated, and getting the right documentation in place before a regulator asks why it wasn't done sooner.
By July 10, 2026, AMLA will issue binding guidelines on business-wide risk assessments. If your back book still contains stale data, missing UBO chains, or risk scores that haven't been recalculated since onboarding, that becomes an audit finding, not a to-do item.
The problem is not that compliance teams don't know their data is stale. The problem is that traditional remediation approaches don't scale.
Why most remediation projects stall
A KYC remediation project at portfolio scale is not a compliance task. It is a programme. And most programmes fail for the same reasons.
Scope is discovered, not defined. Without systematic gap analysis, teams start with the most visible cases and discover the true scope only as they work through the pile. Three months in, the backlog looks bigger than it did on day one.
Outreach falls on the wrong people. Document collection defaults to whoever owns the client relationship. That means senior relationship managers spending weeks on administrative follow-up instead of the work that actually needs their judgment.
Prioritisation is backwards. Without portfolio-wide ranking by risk and gap severity, effort concentrates where it's easiest, not where the regulatory exposure is highest. The most urgent cases wait longest.
Velocity is linear. Manual remediation scales with headcount. The backlog grows faster than most teams can clear it, especially when day-to-day compliance work doesn't stop just because a remediation project started.
Documentation is an afterthought. Remediated files still need a proper audit trail. When that trail is assembled manually after the fact, the quality reflects whatever time was left at the end of the project.
What automated KYC remediation actually looks like
The shift is simple in principle: instead of analysts finding and assembling data for every case, the platform does that work, and analysts make decisions on pre-prepared files.
Here's what that means in practice.
1. Every file compared. Every gap surfaced
Automated remediation starts by comparing every entity in your portfolio against your current data standard and live registry data. Missing documents, outdated ownership information, stale risk scores, all surfaced before a single analyst opens a case.
This is the step that transforms a remediation project from a multi-quarter slog into a structured, prioritised programme. The scope is defined by data on day one.
2. Cases ranked by risk, not by alphabet
Once gaps are identified, cases are ranked by regulatory exposure, risk score, and gap severity. Your team works the highest-risk cases first, not the ones that happen to be at the top of a spreadsheet.
3. Client outreach runs itself
When data is missing, the right form goes out automatically. ID requests, UBO declarations, source of wealth documentation, whatever your policy requires. Submission is tracked in real time. Follow-up runs automatically until the form is completed.
Your team doesn't chase. They review what comes back.
4. AI reads the documents. Not your analyst
When documents arrive, AI classifies, extracts, and validates the data automatically. Updated information flows into the case file without manual re-keying. The analyst opens a pre-prepared case, reviews the changes, and makes the decision.
5. The audit trail builds as the project runs
Every remediation action is logged from the first comparison run. What was checked, what was found, what was updated, and by whom. Progress reporting shows completion rates, outstanding cases by risk tier, and gap resolution status. The trail is complete before anyone asks for it.
6. Remediation ends. Monitoring begins
This is the part most projects miss. Entities that have been remediated should flow directly into continuous monitoring, so the back book doesn't rebuild itself by the time the next review cycle arrives.
If your remediation ends with a clean file that sits untouched until the next periodic review, you're building a future remediation project right now.
The numbers that matter
The comparison and case preparation work that typically takes months runs in days when automated. Processing happens in parallel, so ten thousand entities take the same elapsed time as one hundred. The bottleneck shifts from data gathering to analyst decisions, and since cases arrive pre-prepared and ranked by priority, the backlog clears faster than a traditional programme allows.
For teams that have run remediation projects with Strise:
- Portfolio-wide gap analysis completed in days, not months
- Automated outreach replaces manual document chasing
- Cases ranked by actual risk exposure, not by order received
- Full audit trail generated automatically, not assembled retrospectively
What this means for AMLA readiness
AMLA's July 2026 guidelines will expect firms to demonstrate that their customer data is accurate, current, and defensible. A back book full of stale profiles and undocumented risk decisions is exactly the kind of finding that triggers deeper scrutiny.
The firms that will be ready are the ones treating remediation as an infrastructure problem, something the platform handles, not as a project that gets staffed, run, and then repeated two years later.
If your team is still scoping the problem, the clock is running.
Next steps
If your firm is facing a remediation backlog, or if your periodic review cycle has turned into a perpetual backlog, here's where to start.
Talk to us. Send your RFP or book a meeting. We'll scope the project against your portfolio and show you what Strise processes in the first 48 hours. Book a meeting with Strise →
